ここでは
[math/0604410] Discrete Component Analysis
の Gamma-Poisson モデル(GaP)の ELBO (evidence lower bound) を導出する。
まず、行列の分解がトピックモデルの一種として解釈できること説明する。
次に、モデルのパラメータ推定方法について述べる。
そしてELBOを導出し、最後にRによるシミュレーションを行う。
行列の復習からはじめてトピックモデルの結果だけ理解する
トピックモデルと総称されるモデルの中には様々なものがありますが、ここでは
[math/0604410] Discrete Component Analysis
の Gamma-Poisson モデル(GaP)を紹介します。
トピックモデルはカウントデータ(なにかの数を数えたデータ)の行列が与えられたとき、それをより小さい行列で近似して理解しやすくするためのモデルです。
行列というのはこんな感じの表のことです。

多くのトピックモデルでは、単語の並び順は無視して、単語の出現頻度にのみ注目し、文書ごとに集計した表を利用します。
ここでは簡単のため3単語のみを集計したことにしていますが、もっと数が増えても大丈夫です。
その場合行列が横に長くなっていきます。
トピックモデルではこの行列がいくつかのトピックが混ざった結果生成されたと考えます。
トピックは単語の出現確率の違いで特徴づけられます。
例えば「刀」とか「印籠」という単語が出てくる確率は時代劇だったら高そうですが、現代劇にはめったに出てこなさそうですよね。
このような単語の出現確率の違いが文書のトピックを特徴づけていると考えるのがトピックモデルです。
トピックも行列で表しておくと便利です。

今回の行列はトピックごとの単語の出現確率を表しているので、横合計が1になります。
トピック1は単語3が出る確率が高め、トピック2は単語2が出る確率が高めです。
ここでは簡単のため2種類のトピックのみを考えていますが、もっと数が増えても大丈夫です。
その場合行列が縦に長くなっていきます。
さて、各文書はトピックが混ざった結果出現すると書きました。
たとえば文書1はトピック1が40、トピック2が10出現したとしましょう。
表と見比べながら慎重に計算していくと、この文書の単語の出現頻度は次のようになります。
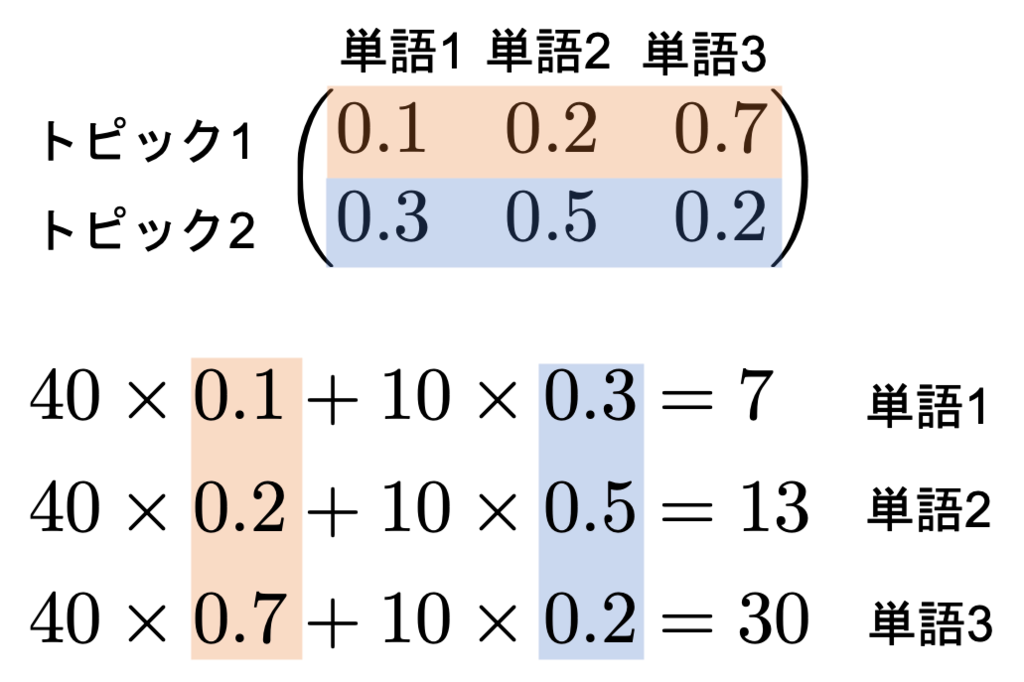
トピック1に40をかけて、トピック2に10をかけています。単語はどちらのトピックにおいても出現確率を持っているので、トピック1から出現した数とトピック2から出現した数を足しています。
このような計算を行列では以下のように省略して書きます。
意味は
とまったく一緒です。
次に文書2はトピック1が20、トピック2が90出現したとしましょう。
行列を使って省略して書くと
となります。
行列ではこの2回の計算をさらに省略して、
と書きます。右辺は1行目に文書1についての計算結果、2行目に文書2について計算結果が入ります。
文書の数が増えても左辺の一個目の行列が長くなるだけで、まったく同じように書くことができます。
以上がトピックモデルのデータ生成過程です。トピックモデルではこれの逆問題をやります。つまり文書と単語の行列がつぎのように与えられたとき、
この行列の分解
を探すのです。
トピックモデルは確率モデルですので本当は
となる行列を探します。 はニアリーイコールです。トピックモデルで得られる行列のかけ算の結果は、もとの行列と厳密には一致しませんが、一致しない分は確率的な誤差とみなすのです。
モデルと変分推論
カウントデータの行列 があるとする。これを2つの正の実数の行列
と
で、
と近似することを考える。
そのために、以下のような生成モデルを考え、 と
を推定する。
このままだと対数尤度にしたとき対数の中に足し算が入る形になり、計算しづらい。なので、ポアソン分布の部分は以下のように書き換える。
ここで である。
こうやって潜在変数 をかますことで平均場近似による近似事後分布は以下のように導ける。
これらはそれぞれガンマ分布、ディリクレ分布である。
ここで
とおいた。
また、ポアソン分布を和で条件付けてやると多項分布になるので、潜在変数については以下の更新式を用いる。
以上をそのまま実装してもアルゴリズムは動くが、更新式をもう少し簡単にすることができる。
潜在変数 についての結果を
に代入すると、
に代入すると、
これにより潜在変数 (3次元配列)を保存することなく、パラメータ推定を行うことができる。
添字に注意して整理すると、 の行列は、
の行列は、
となる。ここで は要素ごとのかけ算、/ は要素ごとのわり算を表す。
ELBO
潜在変数を 、観測されるデータを
としたとき、ELBO は次の式で与えられる.
ここでの期待値は変分事後分布 による期待値。
GaP に出てくる確率(密度)関数の対数をすべて書き下す。
期待値の計算の難しい と
の項はキャンセルされて消える。
また、
であるから、
と、
と、
の項もキャンセルされて消える。
また、
R による実装例
GaPVB <-function(Y,L=2,a=0.5,b=1e-8,alpha=rep(1,ncol(Y)),maxit=500){ N <- nrow(Y) K <- ncol(Y) EelW <- matrix(rgamma(N*L,shape=a,rate=1),N,L) unnorm <- matrix(alpha+colSums(Y),L,K,byrow = TRUE) EelH <- unnorm/rowSums(unnorm) log1pb <- log1p(b) for(iter in 1:maxit){ Sw <- EelW * (((Y)/(EelW %*% EelH)) %*% t(EelH)) Sh <- EelH * (t(EelW) %*% (Y/(EelW %*% EelH))) alpha_W <- a + Sw alpha_H <- alpha + Sh den <- rowSums(alpha_H) EelW <-exp(digamma(alpha_W)-log1pb) EelH <-exp(digamma(alpha_H)-digamma(den)) } EW <- alpha_W/(b+1) EH <- alpha_H/den ELBO <- -sum(lfactorial(Y))+ L*sum(lgamma(sum(alpha))-sum(lgamma(alpha))) + sum(-lgamma(rowSums(alpha_H))+rowSums(lgamma(alpha_H))) + sum(-alpha_W*log1pb+a*log(b)+lgamma(alpha_W)-lgamma(a)) + sum(-Y*(((EelW*log(EelW))%*%EelH + EelW%*%(EelH*log(EelH)))/(EelW%*%EelH)-log(EelW%*%EelH))) return(list(W=EW,H=EH,ELBO=ELBO)) }
簡単なシミュレーションを行ってみる。
N <- 100 K <- 10 L <- 3 W <- matrix(rgamma(N*L,shape=1,scale=1000),N,L) W <- W[,order(W[1,])] unnormH <- matrix(rgamma(L*K,shape=1,rate=1),L,K) H <- unnormH/rowSums(unnormH) Y <- matrix(rpois(N*K,W%*%H),N,K) out <- NMFVB(Y,L=L,a=0.5,b=0) plot(out$W[,order(out$W[1,])],W, main="W", xlab = "estimates", ylab = "true value") abline(0,1,lty=2) plot(out$H[order(out$W[1,]),],H, main="H", xlab = "estimates", ylab = "true value") abline(0,1,lty=2)


Wのスケールが大きい場合、シミュレーションで設定した真値と推定値がそこそこ一致することがわかる。
ただしラベルスイッチングの問題があるので、 となるようソートし直している。
シミュレーション
トピック数を5にしてデータを生成した。
library(parallel) simfunc <- function(i){ set.seed(i) W <- matrix(rgamma(100*5,1,0.001),100,5) H <- matrix(rgamma(5*20,1,1),5,20) H <- H/rowSums(H) Y <- matrix(rpois(100*20,W%*%H),100,20) sapply(1:10, function(L)GaPVB(Y,L)$ELBO) } out <- mclapply(1:100,simfunc,mc.cores = detectCores()) print(table(apply(simplify2array(out),2,which.max))) boxplot(t(simplify2array(out)))

100回のシミュレーション中100回とも正しいトピック数を選んでいる。
> print(table(apply(simplify2array(out),2,which.max))) 5 100